Laboratory Task 6#
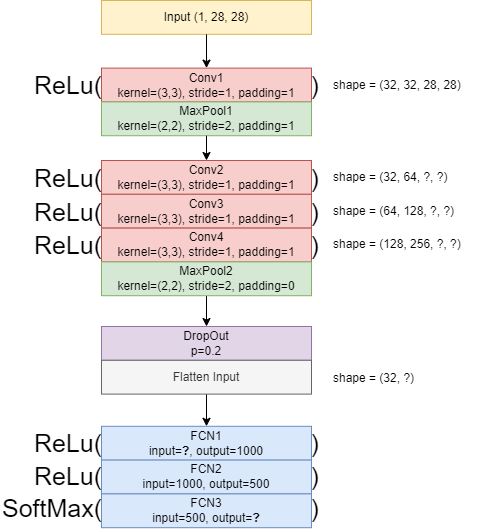
Instruction: Convert the following CNN architecture diagram into a PyTorch CNN Architecture.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import random
import numpy as np
from sklearn.metrics import confusion_matrix, classification_report, accuracy_score
import matplotlib.pyplot as plt
transform = transforms.ToTensor()
train_data = datasets.MNIST(root='data', train=True, download=True, transform=transform)
test_data = datasets.MNIST(root='data', train=False, download=True, transform=transform)
100%|██████████| 9.91M/9.91M [00:03<00:00, 3.00MB/s]
100%|██████████| 28.9k/28.9k [00:00<00:00, 110kB/s]
100%|██████████| 1.65M/1.65M [00:02<00:00, 773kB/s]
100%|██████████| 4.54k/4.54k [00:00<00:00, 1.51MB/s]
train_set, val_set = torch.utils.data.random_split(train_data, [0.8, 0.2])
def set_seed(seed):
np.random.seed(seed)
torch.manual_seed(seed)
random.seed(seed)
set_seed(143)
batch_size = 10
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_data, batch_size=batch_size, shuffle=False)
# Define the CNN architecture
class CNN(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32, kernel_size=(3,3), stride=1, padding=1)
self.pool1 = nn.MaxPool2d(kernel_size=(2,2), stride=2, padding=0)
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64, kernel_size=(3,3), stride=1, padding=1)
self.conv3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=(3,3), stride=1, padding=1)
self.conv4 = nn.Conv2d(in_channels=128, out_channels=256, kernel_size=(3,3), stride=1, padding=1)
self.pool2 = nn.MaxPool2d(kernel_size=(2,2), stride=2, padding=0)
self.dropout = nn.Dropout(p=0.2)
self.flatten = nn.Flatten()
self.fcn1 = nn.Linear(256*7*7, 1000)
self.fcn2 = nn.Linear(1000, 500)
self.fcn3 = nn.Linear(500, 10)
def forward(self, x):
x = F.relu(self.conv1(x)) # shape = (1, 32, 28, 28)
x = self.pool1(x) # shape = (32, 15, 15)
x = F.relu(self.conv2(x)) # shape = (32, 64, 15, 15)
x = F.relu(self.conv3(x)) # shape = (64, 128, 15, 15)
x = F.relu(self.conv4(x)) # shape = (128, 256, 15, 15)
x = self.pool2(x) # shape = (256, 7, 7)
x = self.dropout(x)
x = self.flatten(x)
x = F.relu(self.fcn1(x)) # shape = (256*7*7, 1000)
x = F.relu(self.fcn2(x)) # shape = (1000, 500)
x = self.fcn3(x) # shape = (500, 10)
return x
# Train the model
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = CNN().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
epochs = 5
for epoch in range(epochs):
model.train()
train_corr = 0
for x_train, y_train in train_loader:
x_train, y_train = x_train.to(device), y_train.to(device)
output = model(x_train)
loss = criterion(output, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
pred = output.argmax(dim=1)
train_corr += pred.eq(y_train).sum().item()
model.eval()
val_corr = 0
with torch.no_grad():
for x_val, y_val in val_loader:
x_val, y_val = x_val.to(device), y_val.to(device)
output = model(x_val)
pred = output.argmax(dim=1)
val_corr += pred.eq(y_val).sum().item()
train_acc = train_corr / len(train_set)
val_acc = val_corr / len(val_set)
print(f"Epoch {epoch+1}: Train Acc = {train_acc:.4f}, Val Acc = {val_acc:.4f}")
Epoch 1: Train Acc = 0.9494, Val Acc = 0.9802
Epoch 2: Train Acc = 0.9802, Val Acc = 0.9789
Epoch 3: Train Acc = 0.9847, Val Acc = 0.9878
Epoch 4: Train Acc = 0.9874, Val Acc = 0.9881
Epoch 5: Train Acc = 0.9885, Val Acc = 0.9900
# Testing
true_labels = []
pred_labels = []
with torch.no_grad():
for b, (x_test, y_test) in enumerate(test_loader):
x_test = x_test.to(device)
y_test = y_test.to(device)
test_pred = model(x_test)
test_pred_vec = torch.max(test_pred.data, 1)[1]
true_labels.append(y_test)
pred_labels.append(test_pred_vec)
true_labels = torch.cat(true_labels, dim=0)
pred_labels = torch.cat(pred_labels, dim=0)
confusion_matrix(true_labels.to('cpu'), pred_labels.to('cpu'))
array([[ 975, 0, 0, 0, 0, 1, 0, 1, 3, 0],
[ 0, 1128, 0, 3, 0, 1, 2, 1, 0, 0],
[ 0, 4, 1016, 0, 0, 0, 0, 3, 9, 0],
[ 0, 0, 1, 999, 0, 5, 0, 1, 4, 0],
[ 0, 0, 0, 0, 970, 0, 2, 0, 0, 10],
[ 0, 0, 0, 4, 0, 885, 1, 1, 0, 1],
[ 4, 2, 0, 0, 2, 1, 948, 0, 1, 0],
[ 0, 3, 4, 1, 0, 0, 0, 1017, 1, 2],
[ 2, 0, 0, 0, 0, 1, 1, 0, 968, 2],
[ 0, 0, 0, 0, 4, 5, 0, 3, 2, 995]])